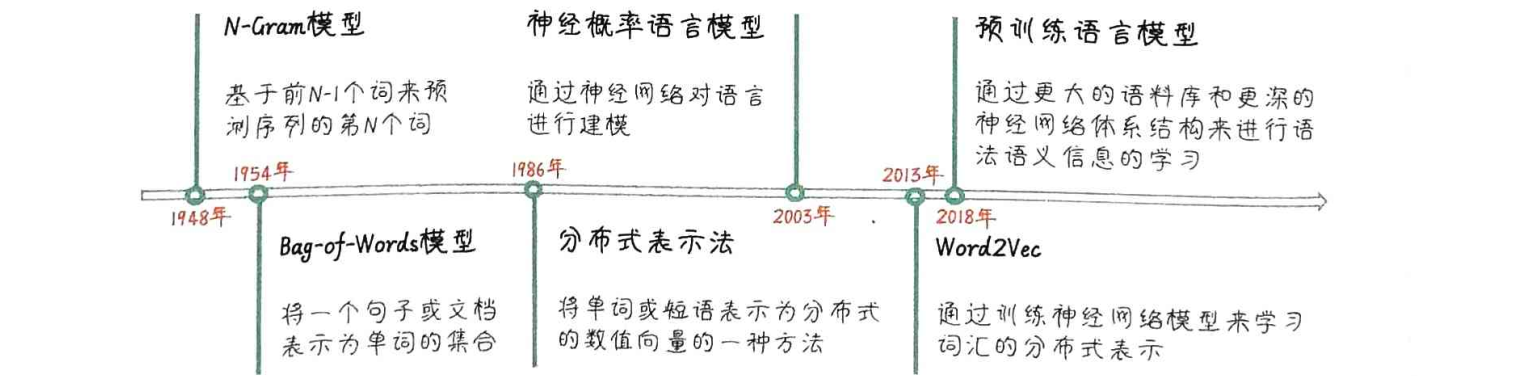
1N Gram和Bag of word
AI技术有两大核心应用:计算机视觉(ComputerVision,CV)和自然语言处理(NLP)。在AI技术发展里程碑中,前期的突破多与CV相关,如CNN和AlexNet;而后期的突破则多与NLP相关,如 Transformer和ChatGPT。
NLP的核心任务,就是为人类的语言编码并解码。NLP的演进过程包括:起源、基于规则(通过基于语法和语义规则的方法来解决NLP问题)、基于统计、深度学习和大数据驱动。
语言模型是一种用于计算和预测自然语言序列概率分布的模型,它通过分析大量的语言数据,基于自然语言上下文相关的特性建立数学模型来推断和预测语言现象。它可以根据给定的上下文,预测接下来出现的单词。
语言模型被广泛应用于机器翻译、语音识别、文本生成、对话系统等多个NLP领域。常见的语言模型有N-Gram模型、循环神经网络(RNN)模型、长短期记忆网络(LSTM)模型,以及现在非常流行的基于Transformer架构的预训练语言模型(Pre-trained Language Model,PLM),如 BERT、GPT 系列等。
基于统计的语言模型具有以下优点。
- 可扩展性:可以处理大规模的数据集,从而可以扩展到更广泛的语言任务和环境中。
- 自适应性:可以从实际的语言数据中自适应地学习语言规律和模式,并进行实时更新和调整。
- 对错误容忍度高:可以处理错误或缺失的数据,并从中提取有用的信息。
- 易于实现和使用:基于统计,并使用简单的数学和统计方法来搭建语言模型。
统计语言模型发展里程碑
在预训练模型发展过程的早期,BERT毫无疑问是最具代表性,也是影响力最大的预训练语言模型。BERT通过同时学习文本的上下文信息,实现对句子结构的深入理解。
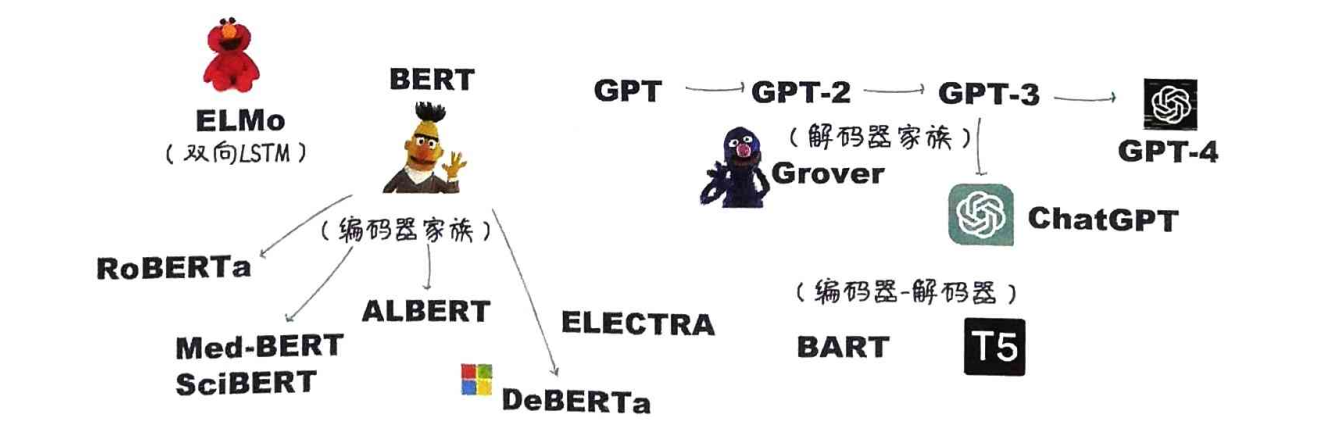
- GPT的预训练过程则类似于做文字接龙游戏。在这个过程中,模型同样通过大量的文本数据来学习,但是它需要预测给定上文的下一个单词(这是单向的学习)。GPT的核心思想是利用Transformer模型对大量文本进行无监督学习,其目标就是最大化语句序列出现的概率。
- BERT的预训练过程就像是做填空题。在这个过程中,模型通过大量的文本数据来学习,随机地遮住一些单词(或者说“挖空”),然后尝试根据上下文来预测被遮住的单词是什么(这是双向的学习),从而学会理解句子结构、语法及词汇之间的联系。
预训练+微调与提示词工程对比
| 特点 | “预训练 + 微调大模型”模式 | Prompt/Instruct 模式 |
|---|---|---|
| 微调过程 | 在下游任务上进行微调以适应需求 | 不经过微调,设计合适的提示或指令生成输出 |
| 学习方式 | 在有标注数据集上进行有监督学习 | 通常不需要有标注数据 |
| 任务适应性 | 通过微调实现较高的任务适应性 | 依赖提示,任务适应性可能较低 |
| 灵活性 | 需要针对每个任务进行微调 | 灵活性更高,不需要微调,可能需要尝试和纠错 |
在大型预训练模型的发展过程中,研究人员发现随着模型参数数量的增加和训练语料库的扩充,大模型逐渐展现出一系列新的能力。这些能力并非通过显式编程引入的,而是在训练过程中自然地呈现出来的。研究人员将这种大模型逐步展示出新能力的现象‘涌现能力”(Emergent Capabilities)。
Ngram
概率模型的基本思想是,给定一个词序列,计算下一个词出现的概率。然而,由于词序列可能非常长,计算整个序列的联合概率会变得非常复杂。在N-Gram模型中,我们通过将文本分割成连续的N个词的组合(即N-Gram),来近似地描述词序列的联合概率。我们假设一个词出现的概率仅依赖于它前面的N-1个词。换句话说,我们利用有限的上下文信息(V-1个词)来近似地预测下一个词的概率。
N-Gram具体怎么玩呢?其实思路很简单,就是统计学。
- 把文本切成小块,每块N个词,比如N等于2就是二元组,N等于3就是三元组。
- 数数每个N-Gram小块出现了多少次,这就是词频。
- 计算条件概率,也就是给定前面几个词,下一个词出现的概率。
- 用这个概率来预测下一个词。本质上就是用历史数据预测未来。
假设我们有语料库,里面有几句话,比如我喜欢你、我爱吃菜、我爱吃肉。我们要用Bigram模型来预测下一个词。比如,我们看到“我爱”,在语料库里出现了两次,而“我”这个字单独出现了十次。那么,根据条件概率公式,给定“我”,下一个词是“爱”的概率就是二除以十等于百分之二十。同理,我们也可以算出“我吃”的概率,假设是百分之一。这样,模型就学会了“我”后面更可能接“爱”。有了这些概率,我们就能生成句子了。比如,我们从“我”开始,根据概率,下一个词是“爱”(概率百分之二十);然后是“吃”(如果“我爱”后面是“吃”,那“吃”的概率是百分之百);再然后是“苹”(“吃”后面是“苹”概率百分之百,因为“吃苹”出现了两次)。把它们连起来,就是“我爱吃苹”。当然,这个例子很理想化,实际生成可能需要考虑更多可能性。
N-Gram最大的问题是,它只看最近的N个词,没法理解长距离的依赖关系。N-Gram里的“元素”可以是很多东西,比如英文里的单词、字符,甚至子词;中文里可以是词、短语,也可以是字。
怎么切分?这就叫分词。英文分词相对简单,中文分词就复杂多了。还有子词分词,比如BERT用的,它能把一个词拆成更小的单元,比如“playing”拆成“play”和“ing”,这样就能处理没见过的词或者拼写错误。
理论讲完了,咱们来点实际的。我们用Python来构建一个简单的Bigram模型,预测字符。流程很简单:
- 构建语料库。比如2句话,比如我喜欢吃苹果,我喜欢吃香蕉,我爱吃橘子。
- 分词 (Tokenize),拆分成字,我喜欢吃苹果就变成了我,喜,欢,吃,苹,果,空格,等等
- 计算词频 (Count N-Grams)。例如我x组合,我喜频率为2,我爱的频率为1
- 计算概率 (Calculate Probabilities),例如我后面接喜概率为2/3
- 生成下一个词的函数。给定一个词从概率表找到下一个最高的概率词即可
Bag-of-word
我们再来看看另一种经典模型——Bag-of-Words,词袋模型。它的思路完全不一样,它不关心词的顺序,只关心每个词出现了多少次。你可以把句子想象成一个袋子,里面装满了各种各样的词。这种模型特别适合做文本分类,比如判断一篇文章是积极还是消极,或者把文章归类到不同的主题。词袋模型怎么用呢?
-
构建语料库 (Corpus)
-
分词 (Tokenize),例如用jieba分词,把每个句子拆成一个个独立的词
-
创建词汇表 (Vocabulary),给每个词分配一个唯一的编号。比如,我就是0,特别就是1,喜欢就是2,可能会很长
-
生成词袋向量 (Generate BoW Vectors),向量里每个维度对应一个词,值就是这个词出现的次数
-
计算余弦相似度 (Cosine Similarity)
词袋模型虽然简单,但也有一些明显的缺点
- 它生成的向量维度很高,因为维度等于词汇表大小,而且大部分元素都是零,这叫高维稀疏性,计算起来效率不高。为解决这个问题,可以使用降维技术,如主成分分析(Principal Component Analysis,PCA)或潜在语义分析(Latent Semantic Analysis,LSA)。
- 它完全忽略了词序信息,无法区分苹果是水果和水果是苹果,也无法理解词语之间的复杂关系。
所以,虽然词袋模型在某些任务上有效,但在需要理解深层语义的场景下,它就显得力不从心了。
总结一下,N-Gram和Bag-of-Words都是NLP领域非常基础但仍然很重要的模型。N-Gram关注词的顺序,擅长捕捉局部上下文,但无法处理长距离依赖,而且容易遇到数据稀疏性问题。Bag-of-Words则完全忽略顺序,只看词频,简单高效,适合文本分类等任务,但丢失了语义信息。它们各有优劣,适用于不同的场景。
| 特性 | N-Gram (语言模型) | Bag-of-Words (文本表示) |
|---|---|---|
| 核心思想 | 捕捉局部顺序 | 忽略顺序,关注词频 |
| 适用任务 | 语言建模, 语音识别 | 文本分类, 情感分析, 信息检索 |
| 优点 | 简单, 易实现 | 简单, 高效 |
| 缺点 | 数据稀疏, 无法捕捉长距离依赖 | 丢失词序信息, 语义模糊 |
| 维度 | 低 (取决于N) | 高 (词汇表大小) |
| 向量 | 稀疏 (通常) | 稀疏 (通常) |