9ray之Serve在线推理服务
现在我们把目光转向另一个关键领域——如何高效地部署和运行这些训练好的模型,特别是那些需要实时响应的应用。这就是我们今天要讨论的在线推理。
什么是在线推理?简单来说,就是让机器学习模型像一个随时待命的API一样,直接响应用户的请求。这跟我们之前在离线场景下批量处理数据、预测结果完全不同。在线推理的核心在于实时性,它要求模型能够快速响应,不能有延迟。想想那些需要即时反馈的场景,比如你刷短视频时,平台会根据你的实时观看行为推荐下一个视频,这就是在线推理的典型应用。推荐系统绝对是在线推理的重头戏。无论是电商平台给你推荐商品,还是社交媒体给你推送感兴趣的内容,背后都离不开在线推理。为什么必须实时?因为用户的心意是瞬息万变的!你今天喜欢这个,明天可能就喜欢那个了。
系统必须能捕捉到用户最新的行为和偏好,比如刚浏览了某个商品,或者刚点赞了某个话题,然后立刻做出推荐。这种基于实时数据的个性化推荐,极大地提升了用户体验。再来看聊天机器人。大家现在用的很多在线客服,背后可能就是AI驱动的聊天机器人。它们可以24小时在线,大大降低了人工客服的成本和响应时间。但这可不是简单的文字匹配,一个合格的聊天机器人需要理解复杂的语言,理解用户意图,甚至进行多轮对话。这背后需要整合多种机器学习技术,比如自然语言处理、情感分析、知识图谱等,而且必须实时响应,才能提供流畅的用户体验。还有我们每天都在用的到达时间预测,比如滴滴、导航、外卖App。它们告诉你司机大概多久到,或者你的外卖多久送到。这看似简单,实则非常复杂。它不仅要考虑固定路线,还要实时追踪路况、天气变化、突发事故等等。而且,这个预测不是一成不变的,而是会随着行程不断更新。没有在线推理,靠人工编写规则,根本无法应对这种复杂性。
在线推理的关键特性
这些在线应用,无论推荐、聊天还是预测,都指向一个共同点:对延迟的极致要求。对于普通用户来说,等待时间长了,体验就差了;但对于自动驾驶、机器人控制这些领域,延迟可能直接关系到安全和效率。所以,低延迟是在线推理的生命线。我们的目标就是在保证模型准确性和服务稳定性的前提下,把响应时间压到最低。为什么在线推理这么难搞?一个关键原因就是机器学习模型本身是计算密集型的。想想传统的Web服务器,大部分请求是读写数据库,I/O操作为主。
但机器学习,尤其是深度学习,本质上是大量的线性代数运算,比如矩阵乘法、卷积运算。这跟传统计算模式很不一样。特别是现在模型越来越深,参数越来越多,对计算能力的要求也越来越高。这也是为什么GPU、TPU这些专门为AI加速的硬件变得越来越重要。除了计算量大,另一个大问题就是成本。很多在线服务,比如电商、社交媒体,都需要7x24小时运行。你想想,一个计算密集型的模型,全天候不停地跑,这得消耗多少CPU和GPU资源?如果模型本身复杂,再加上需要持续运行,那成本简直是天文数字。所以,如何在保证低延迟的同时,尽可能地降低成本,就成了在线推理系统必须解决的核心难题。
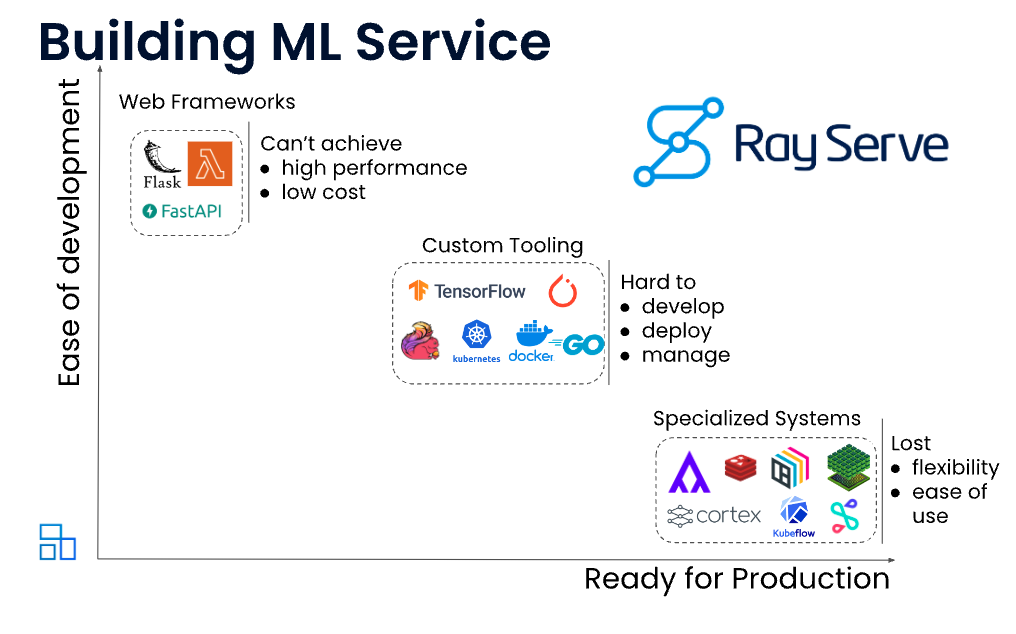
面对这些挑战,Ray Serve应运而生。它是一个构建在Ray之上的、专门为服务机器学习模型设计的可扩展计算层。Ray Serve最大的特点就是灵活,它不挑食,不绑定特定的机器学习框架,无论是TensorFlow、PyTorch还是其他模型,只要是Python代码,它都能处理。更重要的是,它能让你把模型和各种业务逻辑,比如数据验证、规则过滤、结果组合等等,无缝地组合在一起,构建一个完整的在线服务。这正是它解决在线推理挑战的关键所在。
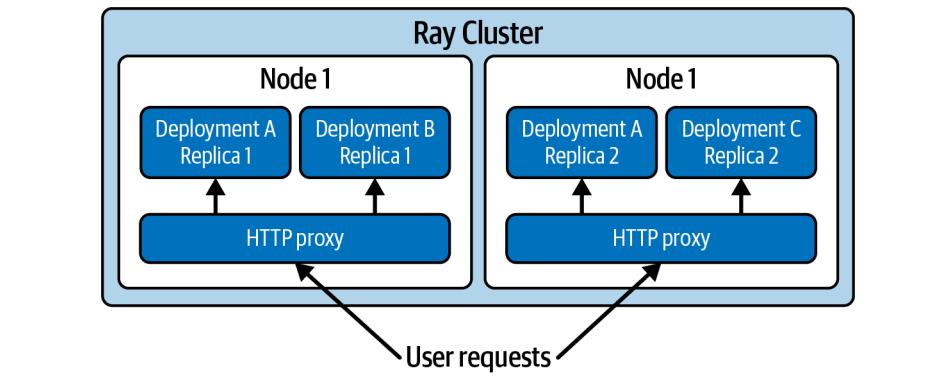
Ray Serve是怎么工作的呢?它最核心的概念是部署。你可以把一个部署想象成一个管理好的Ray Actor集群,它们共同对外提供一个服务接口。每个部署里包含一个或多个Actor,我们叫它们副本。当一个请求进来,HTTP代理会把它分发给这些副本里的一个。背后有个聪明的控制器,负责管理所有这些Actor,确保它们正常运行,如果哪个挂了,控制器将检测到故障,并确保 actor 得到恢复,可以继续提供服务。
我们先来看最简单的例子,把一个模型包装成一个HTTP服务。比如,我们想做一个情感分析模型,判断一句话是积极还是消极。用Ray Serve,只需要定义一个Python类,加上一个@serve.deployment装饰器,告诉Ray Serve这是一个部署。
# app.py
from ray import serve
from transformers import pipeline
@serve.deployment
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
def __call__(self, request) -> str:
input_text = request.query_params["input_text"]
return self._classifier(input_text)[0]["label"]
basic_deployment = SentimentAnalysis.bind()
然后在类里面,__init__方法用来初始化模型,比如加载模型权重,这个过程通常比较耗时,但只会执行一次,非常高效。__call__方法就是处理请求的入口,它接收HTTP请求,调用模型,然后返回结果。最后,用.bind()方法把这个部署定义好。
刚才那个例子处理请求参数有点麻烦,手动写代码解析。Ray Serve还支持和FastAPI集成,FastAPI是现在非常流行的Python Web框架,写起来非常简洁,而且能自动处理输入验证。我们可以把FastAPI的app对象包装成一个部署,然后用@app.deployment和@app.ingress装饰器,这样就能利用FastAPI的路由和参数解析能力,让我们的HTTP API定义更清晰、更健壮。
模型跑起来了,但怎么应对流量高峰?Ray Serve允许我们动态调整资源。比如,可以通过 num_replicas 参数指定一个部署有多少个副本,也就是多少个Actor在同时处理请求。还可以通过 ray_actor_options 参数,比如 num_cpus 或者 num_gpus,来控制每个副本能使用多少资源。
from fastapi import FastAPI
from transformers import pipeline
from ray import serve
app = FastAPI()
@serve.deployment(num_replicas=2, ray_actor_options={"num_cpus": 2})
@serve.ingress(app)
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@app.get("/")
def classify(self, input_text: str) -> str:
import os
print("from process:", os.getpid())
return self._classifier(input_text)[0]["label"]
scaled_deployment = SentimentAnalysis.bind()
更厉害的是,Ray Serve还支持自动伸缩,可以根据当前的请求数量,自动增加或减少副本的数量,实现真正的弹性伸缩,应对流量波动。
还有一个非常重要的优化技巧:请求批处理。很多模型,特别是GPU模型,非常适合向量化计算,也就是把一批数据放一起处理,效率远高于单个处理。Ray Serve提供了 @serve.batch 装饰器,可以自动把短时间内到达的多个请求合并成一个批量请求,然后一次性调用模型处理。这样做的好处是显而易见的:大大提升了吞吐量,降低了平均延迟,尤其是在GPU上,性能提升非常明显。而且,客户端不需要做任何改动,服务器端自动处理,非常方便。
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@serve.batch(max_batch_size=10, batch_wait_timeout_s=0.1)
async def classify_batched(self, batched_inputs):
print("Got batch size:", len(batched_inputs))
results = self._classifier(batched_inputs)
return [result["label"] for result in results]
@app.get("/")
async def classify(self, input_text: str) -> str:
return await self.classify_batched(input_text)
batched_deployment = SentimentAnalysis.bind()
测试部署
import ray
from ray import serve
from app import batched_deployment
handle = serve.run(batched_deployment)
ray.get([handle.classify.remote("sample text") for _ in range(10)])
前面我们讲的都是单个模型的部署,但现实世界中,很多应用需要多个模型协同工作,比如一个推荐系统可能需要用户画像、商品特征、协同过滤等多个模型。Ray Serve的强大之处在于,它能轻松地把这些模型组合起来,构建复杂的推理图。
核心机制是通过 .bind() 方法,把一个部署的引用传递给另一个部署,这样它们就可以互相调用,就像搭积木一样。
@serve.deployment
class DownstreamModel:
def __call__(self, inp: str):
return "Hi from downstream model!"
@serve.deployment
class Driver:
def __init__(self, downstream):
self._d = downstream
async def __call__(self, *args) -> str:
return await self._d.remote()
downstream = DownstreamModel.bind()
driver = Driver.bind(downstream)
部署模式
我们可以用这种方式构建出三种常见的模式:管道、广播和条件分支。
管道模式
想象一下流水线,一个任务做完,下一个任务接着做。比如图像处理,可能先做图像增强,再做目标检测,最后做图像识别。在Ray Serve里,我们可以把每个步骤定义成一个独立的部署,然后在主驱动部署里,依次调用这些步骤,把前一个步骤的输出作为后一个步骤的输入。这样就形成了一个完整的处理流程。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self, inp: str):
return inp + "|" + self._my_val
@serve.deployment
class PipelineDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
intermediate = self._m1.remote("input")
final = self._m2.remote(intermediate)
return await final
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
pipeline_driver = PipelineDriver.bind(m1, m2)
广播模式
有时候,我们想让同一个输入同时跑多个模型,比如做模型集成,或者从不同角度分析问题。在广播模式下,我们把输入数据分发给多个模型并行处理,然后把结果汇总起来。比如,我们可以用一个情感分析模型和一个文本摘要模型,同时处理一篇文章,然后把两个结果都返回给用户。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self):
return self._my_val
@serve.deployment
class BroadcastDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
output1, output2 = self._m1.remote(), self._m2.remote()
return [await output1, await output2]
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
broadcast_driver = BroadcastDriver.bind(m1, m2)
条件逻辑
现实世界不是一成不变的,我们需要根据具体情况做出判断。比如,我们可能想根据用户画像,选择不同的推荐模型;或者,如果检测到输入数据有问题,就跳过某些昂贵的计算。Ray Serve允许我们在驱动模型里写入Python逻辑,比如if-else判断,根据条件动态地选择调用哪个下游模型。这使得我们的推理流程更加灵活和智能。
@serve.deployment
class DownstreamModel:
def __init__(self, my_val: str):
self._my_val = my_val
def __call__(self):
return self._my_val
@serve.deployment
class ConditionalDriver:
def __init__(self, model1, model2):
self._m1 = model1
self._m2 = model2
async def __call__(self, *args) -> str:
import random
if random.random() > 0.5:
return await self._m1.remote()
else:
return await self._m2.remote()
m1 = DownstreamModel.bind("val1")
m2 = DownstreamModel.bind("val2")
conditional_driver = ConditionalDriver.bind(m1, m2)
实战案例
理论讲完了,我们来看一个完整的实战案例:构建一个基于Ray Serve的NLP摘要API。这个API的目标是:用户输入一个关键词,比如“物理学”,API会返回该关键词最相关的维基百科文章的简短摘要和关键实体。我们会用到Hugging Face的Transformers库,FastAPI来定义API,还会用到Wikipedia API来抓取文章。
整个流程包括:搜索文章、情感分析、文本摘要、实体识别,最后组合结果。这个案例会综合运用前面讲到的所有Ray Serve功能。
我们需要获取用户搜索的关键词对应的文章内容。我们用Python的wikipedia库来实现这个功能。它会根据关键词搜索维基百科,返回一系列相关文章。我们选择排名第一的文章,并提取它的正文内容。如果没找到文章,就返回None。
from typing import Optional
import wikipedia
def fetch_wikipedia_page(search_term: str) -> Optional[str]:
results = wikipedia.search(search_term)
if len(results) == 0:
return None
return wikipedia.page(results[0]).content
核心的NLP模型,我们用Hugging Face的情感分析模型,还用上了刚才说的批处理,提高效率。
from ray import serve
from transformers import pipeline
from typing import List
@serve.deployment
class SentimentAnalysis:
def __init__(self):
self._classifier = pipeline("sentiment-analysis")
@serve.batch(max_batch_size=10, batch_wait_timeout_s=0.1)
async def is_positive_batched(self, inputs: List[str]) -> List[bool]:
results = self._classifier(inputs, truncation=True)
return [result["label"] == "POSITIVE" for result in results]
async def __call__(self, input_text: str) -> bool:
return await self.is_positive_batched(input_text)
然后是文本摘要,这个模型比较耗资源,所以我们设置了两个副本,num_replicas等于2。
@serve.deployment(num_replicas=2)
class Summarizer:
def __init__(self, max_length: Optional[int] = None):
self._summarizer = pipeline("summarization")
self._max_length = max_length
def __call__(self, input_text: str) -> str:
result = self._summarizer(
input_text, max_length=self._max_length, truncation=True)
return result[0]["summary_text"]
最后是实体识别,我们还会加一些简单的业务逻辑,比如过滤掉置信度低的实体,或者限制返回实体的数量。这三个模型都是独立的部署。
@serve.deployment
class EntityRecognition:
def __init__(self, threshold: float = 0.90, max_entities: int = 10):
self._entity_recognition = pipeline("ner")
self._threshold = threshold
self._max_entities = max_entities
def __call__(self, input_text: str) -> List[str]:
final_results = []
for result in self._entity_recognition(input_text):
if result["score"] > self._threshold:
final_results.append(result["word"])
if len(final_results) == self._max_entities:
break
return final_results
我们还需要一个主控制器来协调它们。我们用FastAPI来定义整个API的接口,包括请求参数和响应格式。在NLPipelineDriver这个部署里,我们编写了完整的控制逻辑:先用fetch_wikipedia_page抓取文章,然后调用情感分析模型,如果文章是负面的就直接返回错误;如果正面,就并行调用摘要和实体识别模型,最后把结果组合起来,返回给用户。
from pydantic import BaseModel
from fastapi import FastAPI
class Response(BaseModel):
success: bool
message: str = ""
summary: str = ""
named_entities: List[str] = []
app = FastAPI()
@serve.deployment
@serve.ingress(app)
class NLPPipelineDriver:
def __init__(self, sentiment_analysis, summarizer, entity_recognition):
self._sentiment_analysis = sentiment_analysis
self._summarizer = summarizer
self._entity_recognition = entity_recognition
@app.get("/", response_model=Response)
async def summarize_article(self, search_term: str) -> Response:
# Fetch the top page content for the search term if found.
page_content = fetch_wikipedia_page(search_term)
if page_content is None:
return Response(success=False, message="No pages found.")
# Conditionally continue based on the sentiment analysis.
is_positive = await self._sentiment_analysis.remote(page_content)
if not is_positive:
return Response(success=False, message="Only positivitiy allowed!")
# Query the summarizer and named entity recognition models in parallel.
summary_result = self._summarizer.remote(page_content)
entities_result = self._entity_recognition.remote(page_content)
return Response(
success=True,
summary=await summary_result,
named_entities=await entities_result
)
把前面定义好的SentimentAnalysis、Summarizer、EntityRecognition这三个部署,以及它们的参数,比如实体识别的阈值,用点bind方法传递给NLPipelineDriver这个驱动部署。这样,整个推理图就连接起来了。
sentiment_analysis = SentimentAnalysis.bind()
summarizer = Summarizer.bind()
entity_recognition = EntityRecognition.bind(threshold=0.95, max_entities=5)
nlp_pipeline_driver = NLPPipelineDriver.bind(
sentiment_analysis, summarizer, entity_recognition)
然后,运行serve run命令,启动服务。
现在可以用requests库来测试一下,比如查询physicist,看看能不能得到预期的摘要和实体。
import requests
print(requests.get(
"http://localhost:8000/", params={"search_term": "rayserve"}
).text)
今天我们一起探索了Ray Serve这个强大的工具,它为我们提供了构建高性能、可扩展、低成本的在线推理服务的完整方案。它不仅解决了计算密集、资源消耗、实时性要求高的核心问题,还提供了灵活的模型组合方式,让我们能够轻松构建复杂的、包含多种模型和业务逻辑的智能应用。Ray Serve作为一个开源的、通用的解决方案,是构建下一代AI应用的坚实后盾。