2cilium基于标签的网络访问控制
今天我们深探讨了Cilium如何通过L3/L4和L7策略来实现基于标签的网络访问控制,以及如何实现微服务间的最小权限隔离。我们还会了解标签、Endpoint、Identity、Node等关键概念,以及如何处理Node Taints和Unmanaged Pods等实际问题。
Cilium的核心优势在于它不再依赖于静态的IP地址,而是通过Pod标签来定义安全策略。这意味着无论你的Pod在哪里运行,只要它携带了正确的标签,策略就能自动生效,这大大简化了大规模集群环境下的安全策略管理。
L3/L4策略
我们今天就从一个基础的L3斜杠L4策略开始,看看如何限制只有特定组织的舰船才能访问Deathstar服务。
这张图直观地展示了我们刚才说的L3斜杠L4策略。
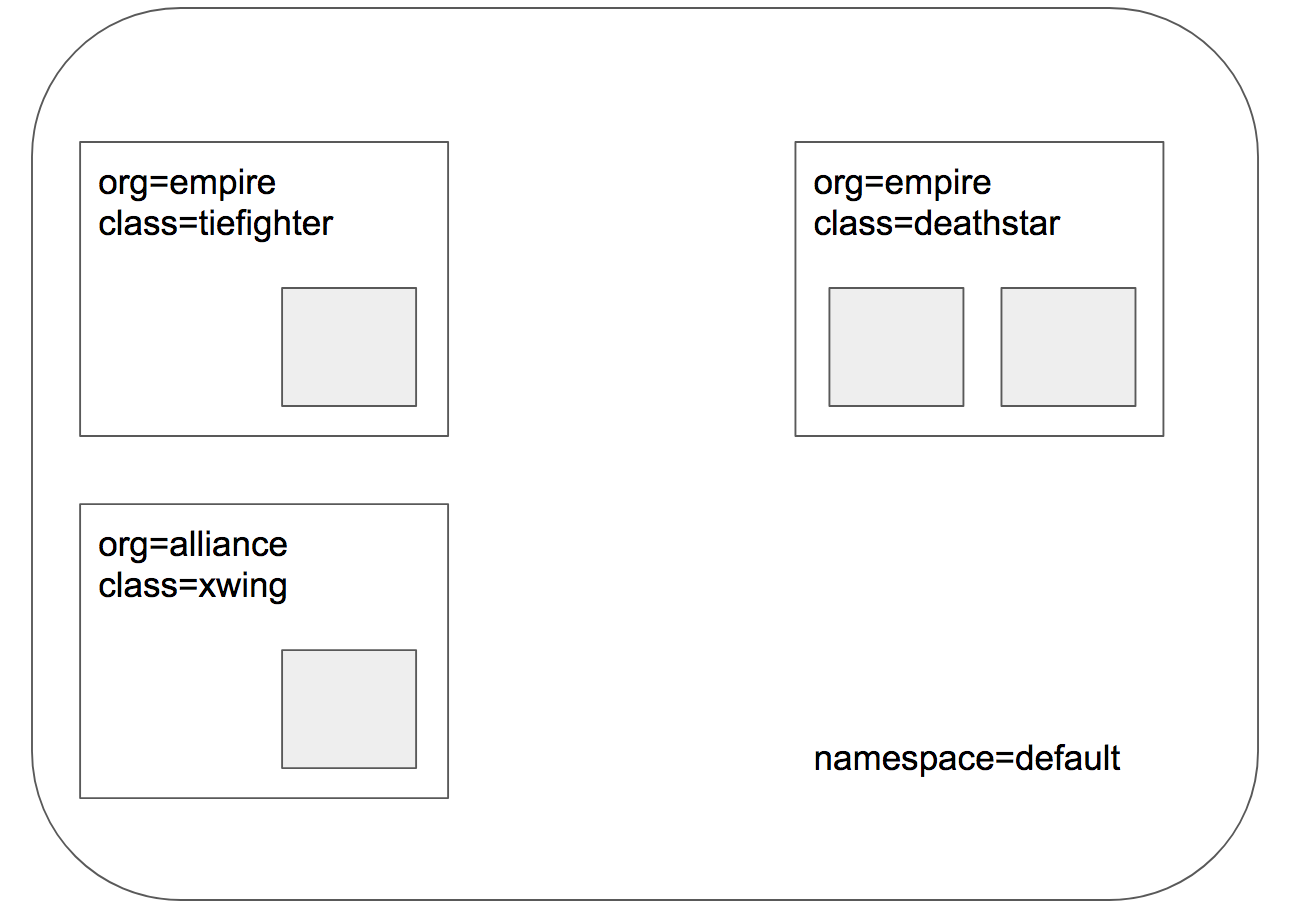
想象一下,Deathstar是帝国的超级武器,它的登陆接口需要严格控制。我们的策略就是,只有那些来自帝国的Tie Fighter舰船,也就是带有org等于empire标签的Pod,才能通过TCP端口80访问Deathstar。而那些来自联盟的X-wing战机,org等于alliance,无论它们怎么靠近,都无法访问这个接口。
这就像给Deathstar装了一个智能门卫,只认帝国的徽章。要实现这个策略,我们需要定义一个CiliumNetworkPolicy,简称CNP。
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "L3-L4 policy to restrict deathstar access to empire ships only"
endpointSelector:
matchLabels:
org: empire
class: deathstar
ingress:
- fromEndpoints:
- matchLabels:
org: empire
toPorts:
- ports:
- port: "80"
protocol: TCP
看这个YAML示例。关键部分在于endpointSelector,它通过matchLabels指定了策略的目标:所有带有org等于empire和class等于deathstar标签的Pod。然后是ingress部分,它定义了允许的流量入口。fromEndpoints再次使用matchLabels来筛选源流量,这里我们要求源必须是org等于empire的Pod。最后,toPorts则精确地指定了目标端口是80,协议是TCP。整个配置逻辑清晰,完全基于标签进行。
配置好策略后,我们只需要执行 kubectl create 命令,将这个 YAML 文件应用到 Kubernetes 集群中。这条命令会创建一个名为 rule1 的 CiliumNetworkPolicy。一旦这个策略生效,集群中的网络规则就会立刻改变,只有符合我们设定条件的流量才能通过。策略部署好了,我们来实际测试一下效果。
我们模拟两个场景:一个是从合法的 Tie Fighter 舰船发起登陆请求,另一个是从非法的 X-wing 战机发起。
如果一切正常,Tie Fighter 的请求应该能成功返回 Ship landed,而 X-wing 的请求则会因为策略拦截而超时或失败。这就像我们之前设定的门禁系统,只有持有帝国徽章的才能顺利通过。为了确认策略确实生效了,我们可以使用 cilium-dbg endpoint list 这个命令。这个工具能直接显示每个端点的状态,包括策略的执行情况。你会看到,那些带有 org等于empire 和 class等于deathstar 标签的 Deathstar Pod,在 ingress policy 列会显示 Enabled,表明它们正在被策略保护。同时,kubectl get cnp 和 kubectl describe cnp 命令也能从 Kubernetes 的视角查看策略的创建和详细信息。
L7策略
刚才我们实现了L3斜杠L4级别的访问控制,但这还不够精细。在微服务架构中,我们需要更强大的能力来实现最小权限原则。比如,Deathstar可能提供了一些维护API,比如排气口,但这些不应该被普通的Tie Fighter舰船调用。如果我们不加以限制,就可能出现像刚才演示的那样,误操作导致Deathstar爆炸的严重后果。这可不是闹着玩的!
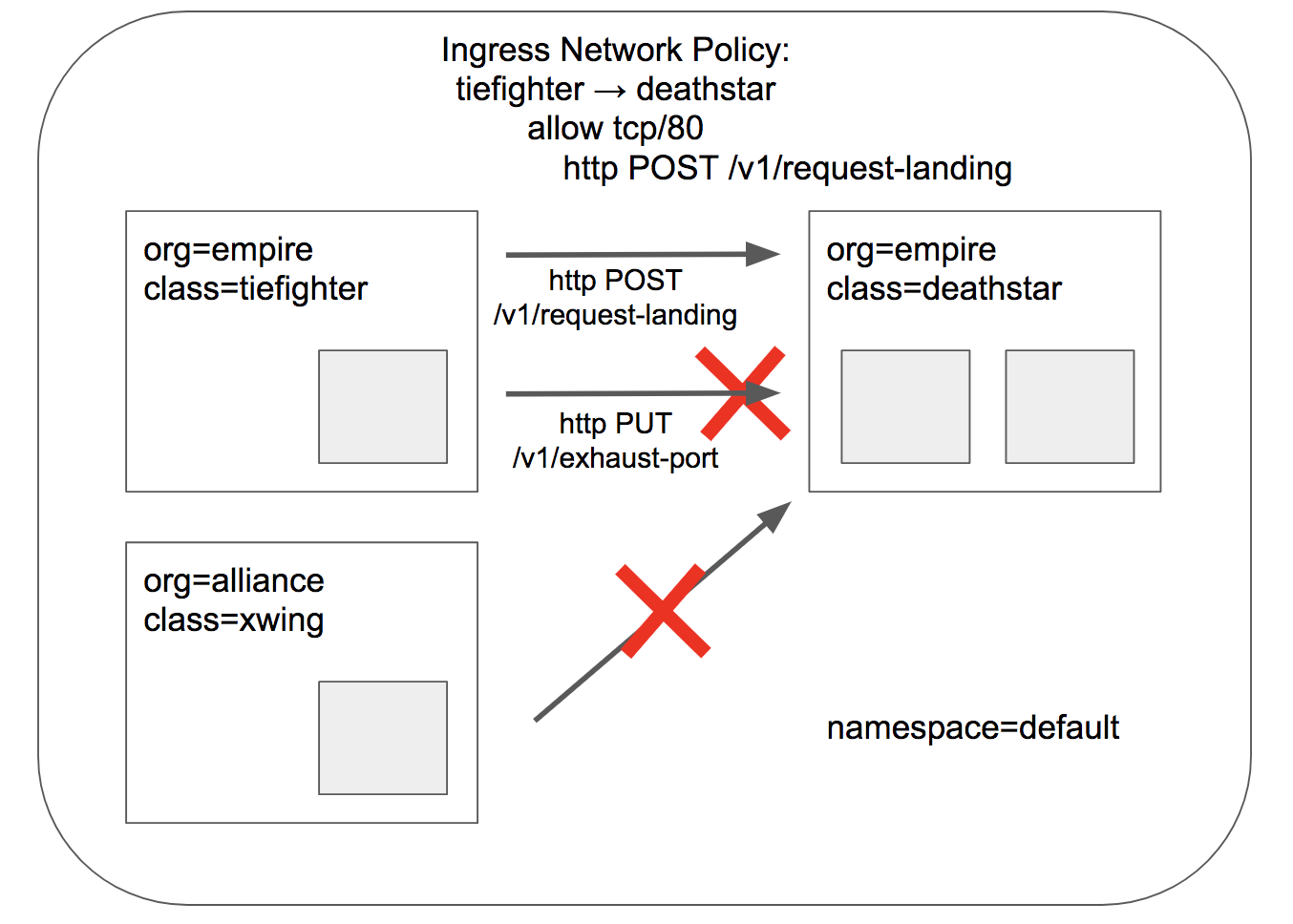
这张图展示了L7策略的威力。它不仅限制了谁可以访问,还限制了可以访问什么。你看,即使是从Tie Fighter舰船发出的请求,也只有POST到斜杠v1斜杠request-landing这个特定路径的请求会被允许。任何其他的请求,比如PUT请求,或者POST到其他路径,都会被直接拒绝,返回Access denied。这就像给Deathstar的控制面板加了密码锁,只允许执行特定的指令。要实现这个L7策略,我们只需要在原来的L4策略基础上,添加一个http规则。在toPorts部分,我们添加了rules字段,然后在http里面定义了method和path。这里我们明确指定只允许POST方法,并且路径必须是/v1/request-landing。注意,如果想匹配一个目录下的所有路径,可以使用正则表达式,比如path: /v1/。这个配置使得策略更加灵活和强大。配置好新的L7策略后,我们使用 kubectl apply 命令来更新现有的 rule1 策略。这个命令会将新的配置应用到集群中。
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
metadata:
name: "rule1"
spec:
description: "L7 policy to restrict access to specific HTTP call"
endpointSelector:
matchLabels:
org: empire
class: deathstar
ingress:
- fromEndpoints:
- matchLabels:
org: empire
toPorts:
- ports:
- port: "80"
protocol: TCP
rules:
http:
- method: "POST"
path: "/v1/request-landing"
由于我们是在原有的L4策略基础上增加了L7规则,所以之前的基于标签的访问控制仍然有效,只是现在访问控制更加深入到了HTTP层。现在我们再次测试。这次我们不仅测试POST斜杠v1斜杠request-landing,还要测试POST斜杠v1斜杠exhaust-port和PUT斜杠v1斜杠request-landing。根据我们的策略,只有POST斜杠v1斜杠request-landing应该成功。其他两种请求,无论是方法错误还是路径错误,都应被拒绝,返回Access denied。这完美地体现了L7策略的精细化控制能力。和L4策略一样,我们可以通过 kubectl describe ciliumnetworkpolicies 来查看策略的详细信息,包括新添加的HTTP规则。更进一步,我们可以使用 cilium-dbg policy get 命令来查看Cilium内部实际应用的策略配置。甚至可以使用 cilium-dbg monitor -v --type l7 这样的命令,实时监控网络流量,观察哪些请求被允许,哪些被拒绝,这对于排错和理解策略行为非常有帮助。
策略相关概念
在深入探讨了策略应用后,我们来回顾一下几个关键概念。
-
首先是标签。标签是Cilium世界里的身份证,它是一种通用、灵活的方式来标识资源。无论是容器还是Pod,它们都可能携带各种标签。这些标签可以来自不同的来源,比如容器运行时或Kubernetes。Cilium会根据来源给标签打上前缀,比如k8s冒号、container冒号等,这样可以避免不同来源的标签冲突。记住,标签是Cilium进行策略选择和身份识别的基础。
-
接下来是Endpoint。在Cilium中,一个Endpoint可以看作是一个共享同一IP地址的容器集合。最典型的就是Kubernetes中的一个Pod。Cilium会给每个Endpoint分配一个IP地址,通常同时是IPv4和IPv6,当然也可以配置只使用IPv6。由于每个Endpoint都有自己的IP地址,它们就可以独立地使用任何端口,比如多个Pod都可以同时绑定80端口,互不干扰。每个Endpoint在节点内部还有一个唯一的ID。Identity,也就是身份标识。这是Cilium用来执行策略的核心概念。每个Endpoint都会被分配一个唯一的身份标识,这个标识是基于Endpoint的安全相关标签计算出来的。这意味着,如果多个Endpoint拥有相同的标签,它们就会共享同一个身份。这大大简化了策略的管理,尤其是在大规模应用部署时。而且,这个Identity是动态的,如果Pod的标签变了,它的身份也会随之更新。
-
并非所有标签都参与Identity的计算。我们需要明确哪些标签是真正用于安全策略的,这些就是所谓的安全相关标签。Cilium默认会识别所有以 id.开头的标签。你可以通过配置cilium-agent来指定这些前缀。比如,你可以定义 id.frontend 和 id.backend 作为你的服务标签,然后基于这些标签来定义策略,Cilium会自动将这些标签纳入Identity的计算。
-
除了由Cilium管理的Endpoint,集群中可能还存在一些不受Cilium管理的网络实体,比如宿主机本身、集群外部的网络等等。为了与这些实体进行通信,Cilium定义了一些特殊的Identity,它们都以 reserved: 前缀开头。比如 reserved:host 代表本地主机,reserved:world 代表集群外部的网络。这些特殊身份的存在,使得Cilium能够管理整个网络环境,而不仅仅是Kubernetes Pod。
-
在某些情况下,比如Cilium启动初期,或者需要与集群内一些关键服务(如DNS、Operator)进行通信时,可能需要预先知道一些常用身份的ID。Cilium内置了一些Well-known Identities,即知名身份。这些身份是预先定义好的,比如kube-dns、core-dns、cilium-operator等。它们的ID是固定的,Cilium启动时会自动识别这些身份,无需额外的配置或查询,保证了Cilium能够快速启动并与其他关键服务建立连接。
-
既然Identity是集群范围内的概念,那么如何保证所有节点上的Cilium Agent都能得到一致的Identity呢?这就需要集群范围内的身份管理。Cilium利用一个分布式Key-Value存储来实现这一点。当一个节点上的Agent需要为一个Endpoint计算Identity时,它会先提取出该Endpoint的标签,然后查询Key-Value存储。如果这个标签组合是第一次出现,Key-Value存储会生成一个新的唯一ID并返回;如果之前已经存在,就返回之前分配的ID。这样就保证了整个集群内,相同标签的Endpoint拥有相同的Identity。
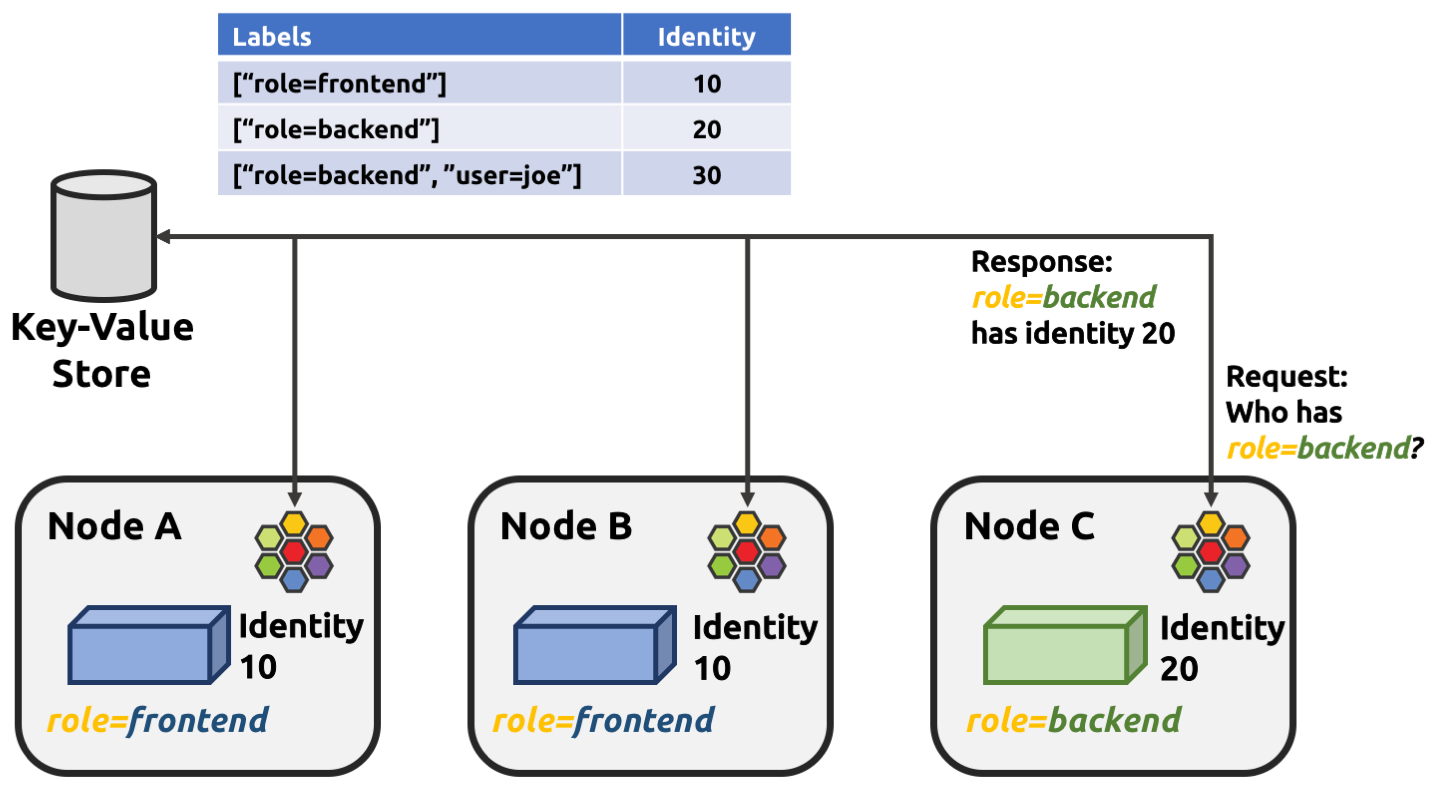
- 在Cilium中,Node指的是集群中的一个物理或虚拟机,上面运行着cilium-agent。每个节点都相对独立地运行,尽量减少与其他节点的同步操作,以保证性能和可扩展性。节点之间的状态同步,主要是通过前面提到的Key-Value存储来实现的,或者在某些情况下,通过网络数据包中的元数据来传递信息。每个节点都有自己的网络地址,包括IPv4和IPv6。Cilium在启动时会自动检测到这些地址,并将它们打印出来。这些地址对于Cilium Agent自身以及与其他节点的通信至关重要。了解节点的IP地址有助于我们进行网络排查和配置。在实际部署中,可能会遇到一些挑战,比如某些云平台可能预装了其他的CNI插件。Cilium尝试接管这些节点,但有时可能无法成功,导致一些Pod在Cilium启动之前就获得了网络配置,成为Unmanaged Pods。为了解决这个问题,Cilium可以利用Kubernetes的Node Taints功能。管理员可以在节点上添加一个特定的Taint,阻止Pod被调度到该节点上。当Cilium成功启动并接管了节点后,它会自动移除这个Taint,从而允许后续的Pod被正常调度和管理。